【教程3】3、编程语言——Verilog语法入门
2024 / 8 / 11
3.1 前言
从具体的项目需求,到实际硬件选型实现、到代码编写等等不是一蹴而就的,这里引入了一部分思考的过程,希望能带领读者过渡到HDL的编程和思考方式。不是说开发板给了你什么,你就做什么;而是你想做什么,开发板给了什么,能做到什么样再考虑怎么写代码。不然你永远都不懂为什么要用这个芯片,如果换成别的怎么处理等等,这个道理放在任何一行都成立——你不能仅仅考虑纯代码conding,也要参与前期的项目设计,硬件选型上。
这些和FPGA可以说没关系,但这是你一定要学会的思考方式。也就是说这玩意是个纯吃经验的,你得经历足够多(或者水足够多群)才能了解到各种项目是怎么落地的。而不是当个只会根据需求,纯coding的工具人。
再次强调,本教程默认读者有一定C语言和51级别单片机基础,没有办法从门级电路开始讲解,讲解啥叫编译,啥叫烧录,抱歉。
3.1.1 对于FPGA开发来说,我们的工作流程是怎样的?
直接设计一个复杂的项目很难了解到FPGA的实际开发流程以及目的,项目的本质是算法,算法的本质是数学,我们先假设一个数学加法项目来了解项目的流程,并进一步了解每一步在FPGA开发中到底在干什么:
假设有一个4bit的数字A和B输入,然后实现输出一个5bit的和,数字C。这里的输入输出指的是相对于芯片内外的信号,比如输入按键、输出LED等,且暂时不考虑多模块调用,仅考虑单文件单模块的工程。我们首先需要在编程软件中创建一个4bit的输入A和B以及5bit的输出C,然后用各种编程方式(编程语言,原理图,逻辑门等)描述A+B到C的过程(代码设计输入),然后将我们在工程里面的ABC每一位设置到FPGA的具体各个输入输出脚上,将外部输入和内部功能通过引脚链接起来(约束设计输入)。然后让编程软件开始编译,这个过程主要要干两件事:将我们的抽象设计(代码、原理图等)转为FPGA直接实现的东西(LUT\ADD,Memory等)(这一步叫综合),然后把这些资源在FPGA芯片上合理的排列(这一步叫布局布线)。然后生成下载文件,就可以烧录下载到FPGA内部运行了(这一步称为板级验证,有bug要调试的)。
对于更复杂的项目来说,还需要在代码编写完成时进行功能仿真,对代码逻辑上分析错误,再进行综合,查看资源消耗是否符合预期;再进行布局布线,进行更为细致的时序仿真以及查看时序分析(主要为Setup和Holdup),在电脑上综合软件自动分析项目中的布局布线路径,结合自动or用户手动给的部分约束,反馈给用户,哪些信号路径实际上是跑不到目标时钟频率的(这部分请跳转到6.3节)。
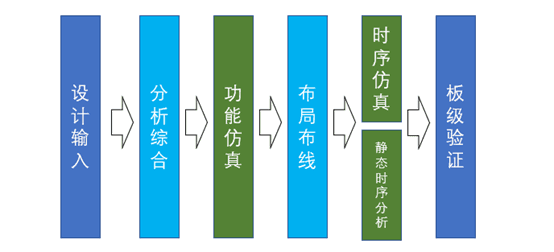 上面这个加法例子看起来很简单,但是只要可使用的资源足够多,结构也可以套的足够复杂。这里我们实现了加法器,同样的方法也可以实现其他的四则运算,同时输入信号也可以来自其他模块的运算结果,这样,复杂的运算加上输入输出引脚,FPGA就能实现指定算法,进而完成项目项目需求。当然,这里如果单纯对FPGA开发还显得比较抽象的话,可以跳到第5章看看具体的从准备到开发的流程。实际的FPGA开发还应该有完善的仿真、时序约束、板级调试等,当然入门或者说简单的项目不需要一定全部走一遍,只需要写好代码和引脚,直接综合布线跳过所有仿真布线直接下载进行debug,一般也是可以实现功能的。
上面这个加法例子看起来很简单,但是只要可使用的资源足够多,结构也可以套的足够复杂。这里我们实现了加法器,同样的方法也可以实现其他的四则运算,同时输入信号也可以来自其他模块的运算结果,这样,复杂的运算加上输入输出引脚,FPGA就能实现指定算法,进而完成项目项目需求。当然,这里如果单纯对FPGA开发还显得比较抽象的话,可以跳到第5章看看具体的从准备到开发的流程。实际的FPGA开发还应该有完善的仿真、时序约束、板级调试等,当然入门或者说简单的项目不需要一定全部走一遍,只需要写好代码和引脚,直接综合布线跳过所有仿真布线直接下载进行debug,一般也是可以实现功能的。
3.1.2 对于具体的功能,我们有什么编程方式?
这就要谈到FPGA的各种编程方式了。但是这里要先收回一个前面的伏笔:为什么一开始的“编程”要打引号?因为FPGA内部的架构是“空的”,我们这里做的工作实际上应该是告诉FPGA哪些模块和线路应该连接在一起,哪些应该断开——这也是FPGA编程语言HDL(Hardware Description Language,硬件描述语言)的名称由来,当然这里怎么“告诉”就是综合布线干的事了。为了简便,以下我们还是以编程称呼,但是读者要自己明白,这里的编程和单片机的那种编程并不是同一种意思。
回到问题,FPGA发展到现在已经有很多种编程方式了:从最传统的原理图编程,到VHDL和Verilog代码编程,再到SystemVerilog以及后面的C/C++甚至Python。当然,主流的还是Verilog,这里其他的编程方式我们还是要介绍一下:
原理图编程:作为FPGA编程中最为底层的编程方式,原理图编程在今日除了“好看”或者怀念一下74系列逻辑门,已经没有什么用处了。但是作为教学工具,在原理图上绘制74系列的电路图以及进行仿真确实还是比玩实际的电路方便的多——但是74系列在今天也没有什么用了,等到74系列退出历史舞台,原理图编程也就失去了唯一的价值。那我为什么说他好看呢?因为在图形化编程里面,数据在线条与图形模块流动,对于初学者来说比较方便理清结构——但是呢,编程软件一般都自带一个RTL viewer,比这个好用多了,所以这玩意也没啥可怀念的价值了。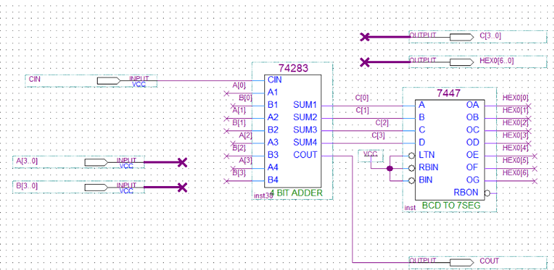
VHDL,Verilog:VHDL先于Verilog出现,一开始是美国军防自己搞的,功能强大,严谨——就是太TM严谨了,学起来比较吃力,于是就有了Verilog……所以Verilog上手更快,语法自由,但是没有VHDL那么严谨。Verilog主要有两个大版本,95版和01版,以年份命名。其实还有05等小版本,但是没有什么质的改变,也就没有成为主流了。
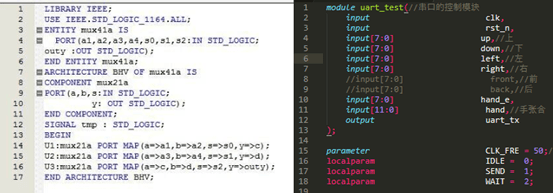
左边VHDL,右边Verilog
SystemVerilog:从01年后,随着芯片功能不断迭代复杂,Verilog不善于做数字芯片仿真验证的缺点逐渐明显,为了大刀阔斧改革,整了个SystemVerilog,兼容以前的Verilog,但是新加了很多语法来适应当前环境的数字芯片开发验证工作,其验证方法思想主要为UVM(咱也不知道,咱也不敢问)。这里引用部分老石关于FPGA入门的观点:1、SystemVerilog是好东西,但是它不适合入门,在学过Verilog以后再来上手,我们仍然需要学习底层的Verilog与硬件的关系,而SystemVerilog一定程度上淡化了这种关系,这对于入门来说不太好。2、至今没有什么比较好的SystemVerilog教程,想要直接入门SystemVerilog有点困难,如果学过Verilog再来自学SystemVerilog就会方便很多了——而Verilog的教程就很多了。但不得不承认,Verilog自05年之后就停止更新了,毕竟新的SystemVerilog更强大,且兼容Verilog语法。除了上面提到的验证方法学以外,在设计上还有方便整理变量的结构体、枚举、利于例化的总线等,再学过Verilog设计一个较大项目的时候,就会体会到SystemVerilog的方便之处了。
C/C++ :虽然HDL一直在发展,但是从二十多年前到现在一直没有质的改变,想要在FPGA上用HDL实现较为复杂的设计和验证算法仍然十分困难。另一方面,资源已经从一开始的几十几百到几十几百万,量变引起了质变,还能一直用Verilog写下去吗?为了将计算机领域的人才引入到FPGA中,各家开发了HLS(High Level Synthesis,高级层次综合)方便人才们通过他们所熟悉的C/C++将那些计算机领域先进的架构带到FPGA中——但是,理想很丰满,现实很骨感。基于FPGA的C/C++开发和原生的C/C++当然不一样,比如不支持动态内存(这本来和FPGA架构有冲突),也不支持系统级的操作(冲突+1)。但咱又不能委屈人家来学FPGA,所以现在正在逐渐的朝原生的C/C++开发靠拢,减少别人开发的差次感,这也是近年来FPGA全球大会的主要方向之一。高情商:战未来!
当然除了xilinx,intel这些厂家自己原产的原汁原味HLS,也有第三方开源的方案,比如chisel、spinalhdl等。有需要的可以自行了解(毕竟我还没学会)。

Python:这里就特指Xilinx的PYNQ了——因为我只用过这个。不好说,没玩明白。我目前知道的原理大概是板载了一个Python的解码器,再转的——不过现在HLS都没玩明白呢,就想着Python了?不过值得一提的是,PYNQ的编程是基于浏览器的,不需要任何编程环境,只需要电脑和开发板在同一局域网下就行,倒是很方便。2025年了这玩意还是没流行起来……
3.2 Verilog
这里你既可以先把编程的软件装起来再学语言,也可以先学语言再学软件。不过我推荐你两边同时学,一边学,一边仿真,理解起来会快一点。当然不装软件也可以直接跳到最下面的在线学习网站开始练习语法。
针对Verilog本身,我想从其数制入手,因为这是FPGA的重要特点之一,然后我们从C语言过渡到Verilog的语法,然后我们从单个语句的语法上升到整个模块的语法和结构,接着我们开始认识不同的模块——也就是时序逻辑和组合逻辑,然后是时序逻辑中非常重要的状态机,最后我们会学习多个模块之间如何相互联系组成一个完整的项目。最后我会提供一个快速在线学习的网站。
本节的重点在于通过Verilog语言实现具体的设计项目需求,但实际的项目开发中还有除了设计以外,还需要仿真验证、时序约束分析、板级调试等。在整个学习FPGA开发的流程中,我们先学习如何设计一个“正确的”程序,至少它是能过编译的,可能在逻辑结构上是有问题的,然后我们再考虑如何验证程序,如何调试程序,如何优化程序。
3.2.1 Verilog中的数制
对于编程来说,最基本的操作就是变量的赋值,所以我们先讲变量可以赋的值有哪些?先从数字开始说起,在C语言编程中,我们说数字10,10加10,我们就在意过它的大小吗?似乎没有,但是它有大小吗?有,如果它是int,就是32位\64位,byte 就是8位,char也是8位,bool是1位。为了优化算法性能,我们常常会把int变量的计算改成short,但有时候我们也在想,32位对于数字10来说会不会太大了,16位好像有点少?这就引出了FPGA编程中的一个重要的特点:变量的位宽是可控自定义的,我们可以想要多少就声明多少,比如17位、21位这种。
举个例子,32’d10,这是Verilog中一个标准的常量数字的写法。拆解分析这个数,有三个部分,前缀32代表这个数是32位的,也就是由32个0或1组成;中间‘d代表是十进制,和C一样,16进制就是’h,8进制就是‘o,2进制就是’b(大小写都可以);第三个部分就是在这个位数和进制情况下的数,比如这个32’d10就是32位十进制的10,当然它也可以写成32‘hA,高位的0可以省略,也可以写成32‘o12,他们都是同一个数,只是不同进制下的表示罢了。
抛开32’9、15‘d1 3这种缺胳膊少腿的写法,详细规则就是:,第一,数制中后面的数要符合前面的进制,比如32’B9、32‘dA就是一个错误写法。第二,后面的数字换算成2进制的位数不能超过前面的数字。这个很好理解,就是前面的数字决定了这个数是由多少位0或1组成了,理论上不可能表示出更大的数,但是声明是没有限制的,软件综合检查时,超出的高位将会被舍弃。比如3’B1110,实际上就变成了3’B110(高位的1被舍弃了,如果是0,舍不舍弃都没有影响——甚至不写都行,默认高位补0)。
在实际使用的时候,需要注意几点:第一,如果什么都不写,就写个10,根据语法会默认为32’d10而不是二进制的2’b10。在乘除的时候可能会当做32位变量浪费资源(尤其是你资源不够用的时候),在实际运用的时候就要想到这点,要多少写多少。另外在拼接操作中{},所有数值变量都必须是指定位宽的,这里即使你真的是32位常量数字也不能省略。第二,在写多位数字时,可以使用下划线作为数字分割。例如32’d1234_5678这样,方便阅读。第三,在做除法时,由于没有小数的设定,所有数据都是整除——推荐放大N倍再除,整数位以下就当小数了,当然不要小数,只乘100倍也行——实际电路做*100的乘法比较麻烦,一般采用左右移来控制放大缩小,这和时序有关,参考后续时序分析章节。第四,在做乘法时,更要注意,如果乘法结果大于实际位数,结果将会出错。比如4‘d10 * 4’d10就不可能得到4’d100。
3.2.2 Verilog中的变量
在传统语法中,Verilog的变量只有Reg和Wire之分。Reg用于表示有明确存储状态的赋值,比如时钟边沿;Wire用于表示状态的传递。比如当a>1的时候某个wire赋值1和Reg赋值1有什么区别?Wire在a信号来的时候就输出1了,a信号中途变化马上变化;Reg则是在固定时间去读a信号,即使读完a后,a信号变化,Reg仍然不受影响。
听起来是不是wire响应更快更好啊?如果电路中全是wire,确实是这样的。但很显然不行,电路中不管多长的wire,下一级一定有Reg。Reg可不惯着你,人家只管到点读数据,如果这个时候wire的信号变化还没到,那这个信号就失效了,后续的所有计算都是错误的。怎么办呢?在wire信号通路上插入一个Reg,这样就变成了wire-新reg-新wire-reg的样子,虽然最后一个reg还是不能第一时间拿到数据,但是信号暂时存在了新reg中,等下一个触发边沿,新reg的信号再传递给原来的reg。最终的结果就是,reg的信号输出慢了1拍,但是信号完整的传下去了,这就是Reg和Wire相辅相成的Verilog编程。
那么Reg就一定是Reg,而Wire也一定是Wire吗?Wire是的,Reg不是。当你的触发信号为*(任意)时,Reg也会被优化为Wire,如下图的Reg b。软件编译过程中,部分Reg也会被优化掉。
那么Reg的赋值_100/100和_*1有区别吗?有,在平时的编写中就应该注意是先乘后除还是应该先除后乘,以及是否存在优化空间。下图展示了即使理论计算公式相同的赋值,在不同写法下,综合结果仍然不一样,尤其是Total logic elements的消耗。
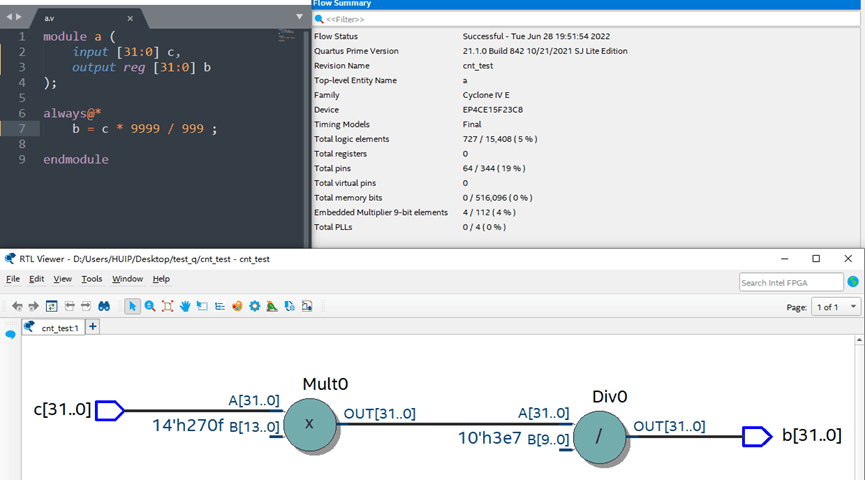
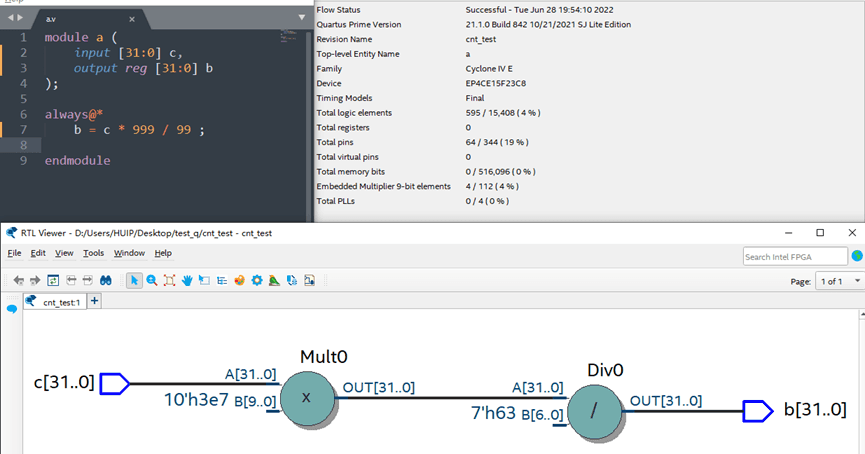
注:对于Verilog数制,建议在后面的仿真章节中,仿照写一个加减乘除,在波形仿真的时候,看看FPGA是怎么怎么处理负数和正数的加减乘除,数据溢出等问题的
除了单个数值以外,我们经常会用到数组,在C语言中我们知道可以写成int C[3] = {1,2,3},那么在verilog中呢?这里我们是写成reg [31:0] C [2:0] 。其中reg [31:0]和int声明对应,C是命名,[2:0] 和 [3]对应,翻译过来就是声明了一个32位的reg变量,地址从0到2一共3个——注意这里[0:2]并不是有8个数据,实际上只有3个,和前面的[31:0]不同。这里可以看出的是verilog更加强调位操作,使用时也是C[1]这样来调用各个元素。
需要注意的是,数组类的变量在Verilog中不允许在不同文件中传递,只能传单个变量。在SystemVerilog中已经增加了这个用法,在学习完FPGA入门以后可以逐渐过渡到SystemVerilog的学习。
ps:那么如何理解 reg [2:0] c [15:0] 和 reg [15:0] c [2:0], 那么reg [2:0] c [15:0] [15:0] 和 reg [2:0][15:0] c [15:0]的区别呢?
除了数字变量以外,常用的赋值还有单个字符(转义字符)、字符串,以及汉字。在Verilog中它们都是可以实现的,其中对于单个字符和字符串来说没啥区别,单个字符遵守ASCII的码表,每个字符8个bit,从左往右,从高到低赋值。ASCII类的字符与其十六进制在赋值和判断中等效(其中不可打印的字符可以使用转义字符,如“\n””\r”),甚至可以做加减(如下所示)。但汉字就没那么容易了,虽然汉字作为字符可以直接赋值给变量,但是在处理和识别的过程中比较麻烦,首先一方面是因为汉字的编码没有像ASCII那么统一的编码,GB2312?UNICODE?UTF-8?哪一种才是能用的?还得做协议编码的识别?(虽然实测下来在Verilog中的汉字字符是当做24位的UTF8编码,根据赋值的位宽进行高位截断,比如下图的变量d实际上只拿到了字符“好”的UTF8 24位编码中的低八位)。另一方面,汉字的编码通常是16或者24bit,单个串口发送周期只能发送8bit的数据——这对于ASCII刚好一个字符,但是对于汉字来说就得两个周期了,嗯……就是要麻烦一点改改代码了。
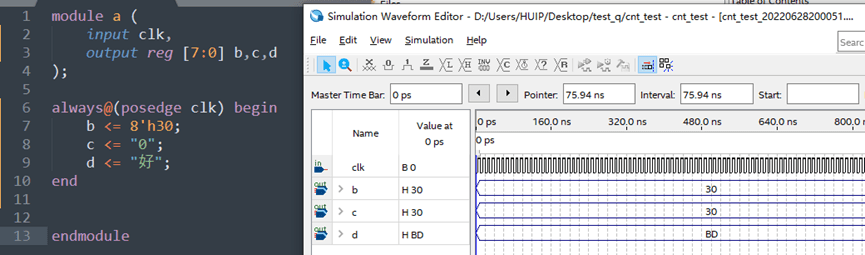 然后我们再来说一下字符串,不同字符可以使用字符串直接拼接,通过地址索引取到指定字符的值,如下所示。(ps.十六进制0D0A就是回车换行)
然后我们再来说一下字符串,不同字符可以使用字符串直接拼接,通过地址索引取到指定字符的值,如下所示。(ps.十六进制0D0A就是回车换行)
 最后我们再说除了高低电平01以外的两种赋值状态,一种是X,一种是Z。其中X用于判断,而不用于赋值。比如casex里分支判断变量 为3’b1xx,即包含了111,110,101,100,这里的X表示任意值;而Z用于赋值而不用于判断,通常用于inout等双向通信端口(input output为单向通信),当变量赋值Z时切换为输入状态,通过三态门的使能切换输入输出功能,这点在以后的学习中会遇到。
最后我们再说除了高低电平01以外的两种赋值状态,一种是X,一种是Z。其中X用于判断,而不用于赋值。比如casex里分支判断变量 为3’b1xx,即包含了111,110,101,100,这里的X表示任意值;而Z用于赋值而不用于判断,通常用于inout等双向通信端口(input output为单向通信),当变量赋值Z时切换为输入状态,通过三态门的使能切换输入输出功能,这点在以后的学习中会遇到。
3.2.2 Verilog中的语法
当然在学习Verilog语法前,再次强调,默认读者有一定的C语言基础了。
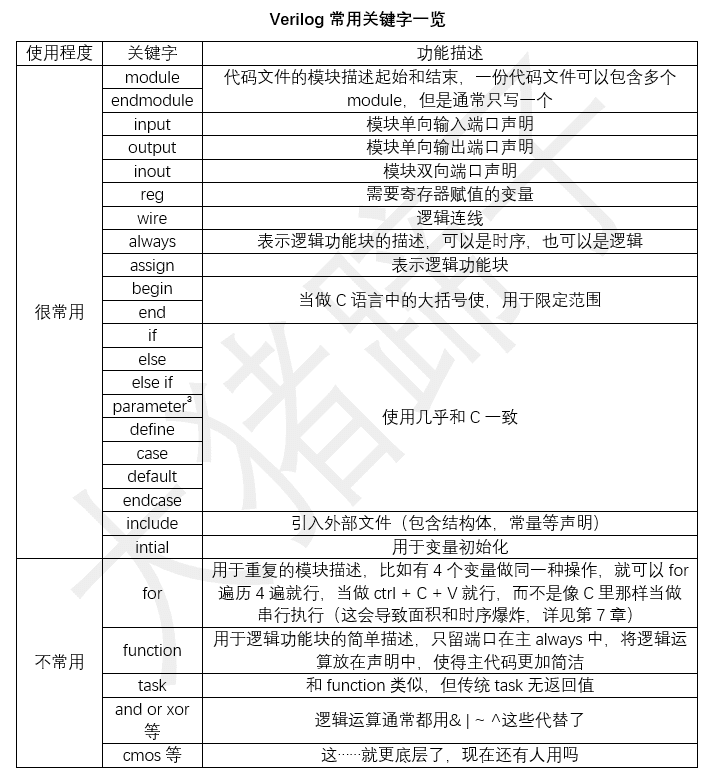
二者关键字差别很大,不过两个都对大小写敏感(就是说if是关键字,IF就会被识别成变量),Verilog只有if,else等基本语法这种保留了下来,就不再和C做对比。所有常用关键字与使用情况归纳如下。
-
注: 这里的define和parameter在后来的语法更新中,允许单独写在一个头文件中,在各个代码里include了。其中parameter还有参数传递,以及local和全局之分,这点和C也是一致的。
-
initial的使用比较有争议,详见后续讨论,这里不展开
 也就是说,从单个语句的执行上来说,Verilog其实和C基本一致,去掉复杂的循环和指针内容甚至还要再简单一点。当然这里我们不能从单个语句来推断计算机和FPGA的差异,因为他们在高一层的理解——执行结构上面就开始有比较明显的区别了。
也就是说,从单个语句的执行上来说,Verilog其实和C基本一致,去掉复杂的循环和指针内容甚至还要再简单一点。当然这里我们不能从单个语句来推断计算机和FPGA的差异,因为他们在高一层的理解——执行结构上面就开始有比较明显的区别了。
这里需要指出的是,同样在SystemVerilog中,增加了结构体、--以及++等操作,有需要可以在学习入门完成后过渡到SystemVerilog的学习。
ps:在SystemVerilog中已经将reg wire二者合二为一。统一用logic这个关键字,这里就不展开了。
3.2.3 Verilog中的结构
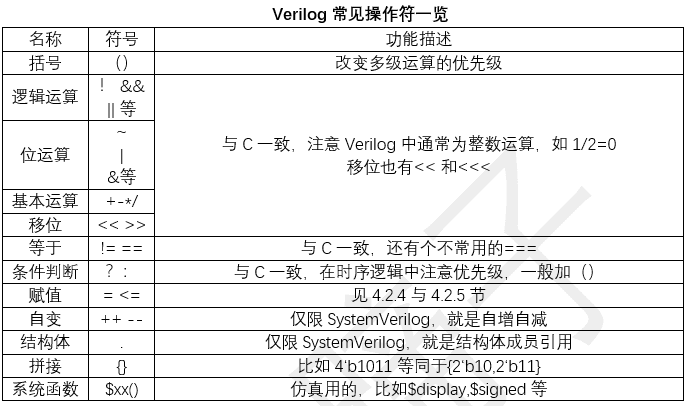
这里我们用一个简单的加法器来做个示例(如下图所示)。
 先说最外面的框架,也就是module test();……endmodule。Module和endmodule通常是一起使用的,写在开头就是说我要写一个“部件、模块”,test是它的名字,括号内是这个“部件”的输入和输出,从module到endmodule是一个部件(一般不推荐在一个代码文件里面写两个及以上的module)
先说最外面的框架,也就是module test();……endmodule。Module和endmodule通常是一起使用的,写在开头就是说我要写一个“部件、模块”,test是它的名字,括号内是这个“部件”的输入和输出,从module到endmodule是一个部件(一般不推荐在一个代码文件里面写两个及以上的module)
我们来看括号内的内容(绿框):input [3:0] A,B,代表我声明了一种输入,A和B,两个输入都是4位,且最低位为0开始到3结束(因为可以写成[1:4]就是最低位1到4结束)。B后面是逗号,因为后面还有声明一种输出:output [4:0] C,就是说这是一个5位宽的输出(因为4位+4位有可能结果是5位)。C后面没有新的声明,所以C后面就是空的,没有逗号(这里多写一个逗号在宽松的语法编译中会视为一个warnning,在vivado等严谨的编译中视为error)。需要注意的是由于语法设定,input和output默认是wire,不能被赋值,也就是说不能直接写C = A + B。
因为上述原因,我们来看下面蓝框的内容。这部分通常为这个部件内使用的变量声明和wire的赋值。由于C不能直接被赋值,我们声明了一个C_temp的reg类型来做A+B的加法,并把这个值通过assign交给C。
最后来看红框部分。这个一般才是代码的主体,它代表处理这个过程。Always@(_)意为只要有触发信号,就执行下面的代码。在这里触发信号设为_,也就是啥没有,也可以理解为随时待命。Begin end在这里就是个括号的作用。中间一行就是加法的代码。连起来就是只要有任何信号变动,就会执行一遍下面的加法代码。而通过上面的assign可以看出,加法结果通过C_temp又交给了C,这样就有了输出C = A +B的效果。
Verilog的代码结构也可以有略微的变动,比如刚才的C = A + B就可以改成这样(如下图所示):output端口直接做成reg类型声明就可以直接被赋值了。

不同的写法主要是Verilog在1995年旧规范和2001年新增的规范
认识完一个简单的Verilog程序后,一个更复杂的Verilog程序应该是怎样的?
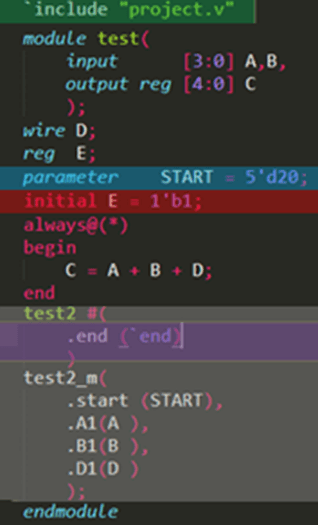 我们从上往下认识新加的代码:
我们从上往下认识新加的代码:
绿框:引入外部代码文件,多为一些define或parameter的常量,或者是各种外部引入参数或者是配置文件等
蓝框:定义本文件的局部使用的常量
红框:初始化变量值(如果不这样干,有可能初始值随机,大多数情况下为0
灰框:引用其他module(这就叫例化,下面会讲)
紫框:引用include的文件中的define 等参数
还有更复杂的结构,如果你还能学下去就可以自行探究了。学到这里应该能应付本科了。
3.2.4 Verilog的组合逻辑
C语言是顺序语言,也就是说执行语句从上到下是依次执行的;但是在Verilog中,所有被触发的always语句都是同时并行运行的,是不是很难理解,我们可以一步一步来,大体上Verilog中的逻辑结构分为组合逻辑和时序逻辑,这里先介绍组合逻辑。
所有的逻辑运算关系都是组合逻辑,比如与或非逻辑门,比如要实现if语句需要做的比较器,比如乘法器等,比如所有的编码译码器。他们的特点为,输入信号通过ns级别的电路固有延迟就直接输出,不在电路中做停留。一般用=号赋值,但是如果“不小心”写成了<=实际上也不会有影响,接下来我们会深入说明。一般纯~组合逻辑电路以always@* 开头,always@是触发的意思,而 *号是任意的意思。
这里我们用一段最简单的代码来示意组合逻辑电路的运行规律,在仿真(见下面章节)中给定输入A一定信号,观察不同操作下的BCDE的输出结果:
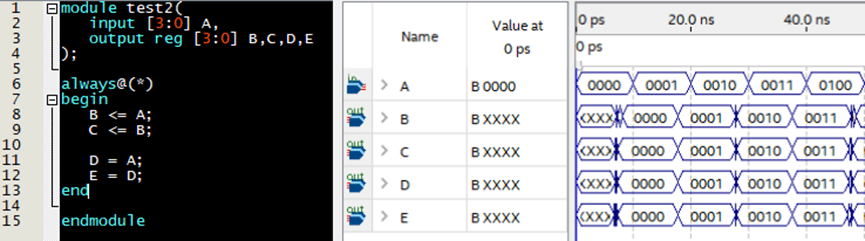
左边是代码,右边是仿真结果
根据仿真结果,我们得出了三个结论:
1-通过对比A>B>C,A>D>E得出<=和=在组合逻辑电路的结果中没有区别;
2-通过对比A>D和A>B得出逻辑电路输入输出有一定的电路延迟(具体大小在以后章节有介绍);
3-通过对比0001变化到0010组合逻辑结果输出电平变化需要一定时间。
思考1:组合逻辑中的两条阻塞语句是否存在运行的先后顺序?
根据刚刚的结论2和结论3就可以推出一个数字电路中的重要问题:组合逻辑电路中的竞争冒险。对于多输入驱动一个输出的的组合逻辑电路来说,没有办法保证所有的输入信号同时到达(这是竞争)——进而导致输出状态会先产生一个由不完全输入导致的信号,再等所有输入信号齐全后,再转为正确的信号——这个不完全的信号就会产生毛刺(这是冒险)。那么应该怎么解决呢?不解决,解决不了了,等死吧……啊哆啦A梦,故事不是这样的,下面要讲的时序电路的目的之一就是解决这个。
3.2.5 Verilog的时序逻辑
上面说的“不解决”并不是说笑,这里可以换另一个角度来理解:对于组合逻辑的竞争冒险来说,我们似乎在意电路“每时每刻”的变化,在乎输入输出的连续的过程——实际上这并不现实,我们只需要它在需要的瞬间保持稳定,我们利用这个稳定的状态进行计算并锁存结果下来,这就是时序电路的本质。这样即使电路在不需要的时间产生了毛刺,也不会对实际有任何影响。
这个需要的瞬间就可以理解为时钟的边沿,无数个采集“瞬间”并处理组成的电路就叫时序电路——因此,在时序电路中,我们只考虑电路“瞬间”的信号状态,对于理论上这就成为一个离散信号的问题了。需要注意的是,为了规范化,这个“瞬间”是等间隔的,正式名称我们叫它时钟。
可能还是有读者不理解:那么时序电路是怎么解决竞争冒险的?嗯……它就是没有解决,等间隔的设计就是保证在竞争冒险的毛刺变化的最大时间值之后进行采样。比如每次输入竞争冒险会产生1~2ns的毛刺信号以后再稳定,那我就每输入之后的3ns做一个时钟边沿去采“瞬间”的信号,它是不是就是稳定的了?
引入时钟后,绝大多数的竞争冒险问题都可以在时钟的间隔周期内避免——但是时钟一般是固定的,我们往往是需要在规定的时间间隔内设计并优化电路,使所有的电路竞争冒险控制在一个时钟周期内。但是有时候因为代码设计问题,比如代码计算量过大,导致电路计算延时过长甚至超过时钟周期,因此还是会出现电路竞争冒险超过时钟周期,具体为什么?怎么办?这就是后面章节静态时序分析的问题了。(有时候不怪代码,有些系统时钟就是很快,留给用户的可操作空间很小,比如上百M的系统,用户操作都会分成几步小的来避免这个问题)
总结:组合逻辑电路有明显的电路延迟,不同的逻辑电路延时不同,为了统一系统运行规律,这里引入了时钟的概念。时钟是一个周期性电平01变化的信号,在绝大多数逻辑电路在时钟的上升沿(posedge)时引入新的、稳定的数据输入,只要保证处理的算法逻辑电路延迟在一个时钟周期内,就能保证整个系统按照时钟的规律性稳定的运行(少数是上下边沿都驱动的比如DDR内存,极少数只有下降沿negedge驱动的)。这里可以将时钟理解为电路的发条,每一下上升沿即驱动电路“工作”一次。因此时序电路中通常会有CLK(时钟信号),寄存器(保存信号状态),触发逻辑(计算信号)等。
我们依旧以刚才的代码为例,但是加入时钟信号。如下图所示,我们从这个代码认识Verilog中的时序特点:
 根据仿真结果,我们也得出了时序电路三个特点:
根据仿真结果,我们也得出了时序电路三个特点:
1-输入的数据不是完全有效,以时钟边沿时刻为准。Posedge就是以上升沿执行,negedge就是以下降沿执行。如果数据维持的时间小于一个时钟周期,就很有可能采集不到(如红框所示)。
2-每次触发特定时钟边沿,代码就会从always开头全部执行一次(如绿框所示)。这点和C语言差别很大了,C的代码一般来说不会从头再跑的。
3-阻塞和非阻塞赋值的差别。这里可以对比BCDE,四种相互对比。<=叫做非阻塞赋值,同一个always中的<=会同时执行。这就造成了绿框内的情况——B直接被赋予A的值同时C被赋予B的值。由于这两步是同时进行的,就导致C被赋予的值是B的旧值,也就造成了图中所示,C的数据变化时钟要慢B一个时钟周期。再说=,这个就叫做阻塞赋值,也就是说同一个always中上一个=语句执行完才会执行下一个=语句。在这个代码中,上一个语句D已经被赋予了A的值,才执行把D的值赋给E,所以DE的值在仿真中始终保持一致。不过一般来说,我们不建议在时序逻辑中使用阻塞赋值。
再次强调:如果不能保证中间处理的电路延迟在一个时钟周期内呢?这就是后面静态时序分析章节的内容了。
思考:在时序逻辑中两种赋值方式都可以,那为什么只让使用<=?
3.2.6 Verilog的组合逻辑与时序逻辑混用
对于大多数人来说,阻塞赋值比较符合一开始的学习思考——但是这并不利于高频率电路实现。我们在学习熟练后就需要转向非阻塞赋值,这里给出了在转变过程中,阻塞逻辑和非阻塞赋值混用情况下容易出现的两个问题。这里给出两份代码及其仿真来说明情况。
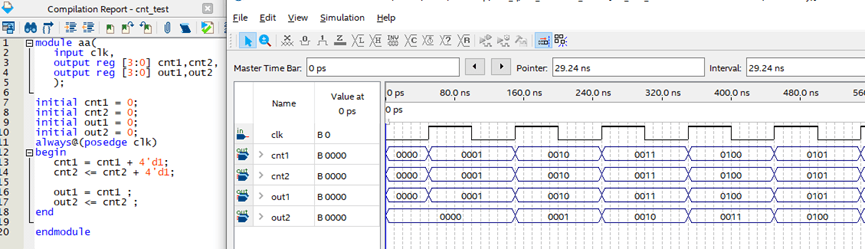 第一:赋值关系。这里把部分内容单独提出再说一遍:在时序逻辑中(always@(posedge clk)),对于被赋值的变量(=号左边)来说,阻塞赋值和非阻塞赋值并没有区别,如上图cnt1和cnt2。但是对于赋值的公式代码来说(=右边),含有的变量是阻塞赋值还是非阻塞赋值是有区别的,如上图out1,和out2。
第一:赋值关系。这里把部分内容单独提出再说一遍:在时序逻辑中(always@(posedge clk)),对于被赋值的变量(=号左边)来说,阻塞赋值和非阻塞赋值并没有区别,如上图cnt1和cnt2。但是对于赋值的公式代码来说(=右边),含有的变量是阻塞赋值还是非阻塞赋值是有区别的,如上图out1,和out2。
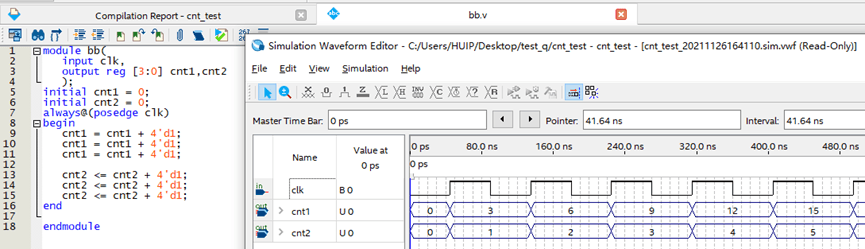 第二:叠加覆盖关系。对于阻塞赋值来说,同一个always内的顺序执行代码会叠加顺序执行,所以三个+1语句都执行了最后效果就是+3;而非阻塞代码只会执行最后一个赋值语句,所以即使有三行+1语句,实际上只执行了最后一个+1。
第二:叠加覆盖关系。对于阻塞赋值来说,同一个always内的顺序执行代码会叠加顺序执行,所以三个+1语句都执行了最后效果就是+3;而非阻塞代码只会执行最后一个赋值语句,所以即使有三行+1语句,实际上只执行了最后一个+1。
我个人对非阻塞与否的理解是:在时序逻辑中使用非阻塞赋值和原有代码属于并行关系,依附关系,设计开发和维护比较容易;使用阻塞赋值是在原有设计的寄存器关系中“插入”了新加的阻塞赋值代码,破坏了原有的静态时序分析关系(如果有的话),使原来能跑到的频率跑不到了,造成后续设计维护比较困难……在下面这个例程中,cnt1和cnt2是完全相同两个计数器,红框为计数器本身的结构,out1作为阻塞赋值是“插入”到原有的组合逻辑后面,增加了电路最大延迟,降低了频率。而out2是并行关系,并没有增加原有框架延迟。
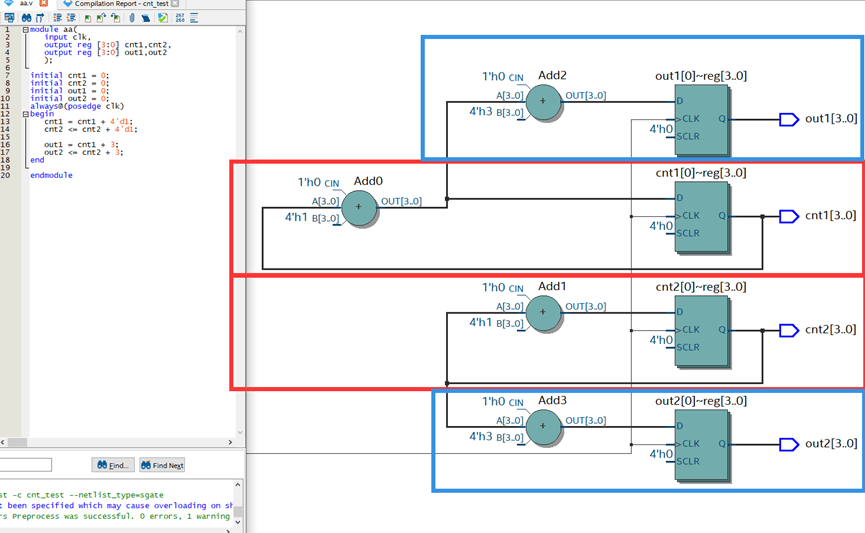 **从设计的角度考虑。**如果要定量分析的话,在只考虑组合逻辑延迟的情况下,假设每个ADD延迟1ns,上半部分的最大延迟为(ADD0+ADD2)=2ns,最大运行频率500Mhz;下半部分的两个ADD为并行关系,最大延迟为两个ADD中延迟最大那个,在这里仍然为1ns,最大运行频率1000Mhz。**从维护开发的角度考虑,**已有的工程可能就是按照1000Mhz去设计优化的,你只能并行加点逻辑,不能往优化好的结构里面“插”,这就是上面所说的破坏了原有的静态时序分析。
**从设计的角度考虑。**如果要定量分析的话,在只考虑组合逻辑延迟的情况下,假设每个ADD延迟1ns,上半部分的最大延迟为(ADD0+ADD2)=2ns,最大运行频率500Mhz;下半部分的两个ADD为并行关系,最大延迟为两个ADD中延迟最大那个,在这里仍然为1ns,最大运行频率1000Mhz。**从维护开发的角度考虑,**已有的工程可能就是按照1000Mhz去设计优化的,你只能并行加点逻辑,不能往优化好的结构里面“插”,这就是上面所说的破坏了原有的静态时序分析。
思考:你知道为什么output虽然可以不带reg,但是都推荐带reg了嘛?
3.2.7 Verilog中的状态机
加上时钟是对组合逻辑的一大重要改进,真正发扬光大的是状态机。也就是说状态机一定是时序逻辑,但是时序逻辑不一定是状态机。时钟只是表象,添加时钟背后的意义相当于把组合逻辑升了一个维度——多的这一维就是时间。光看理论短时间确实比较难以理解,希望读者能结合实际工程和状态机这些具体的应用来理解。
在实际项目中很讲究并行处理设计,毕竟这是FPGA的特点。但是能做成并行操作加速的代码毕竟是少数,想要用FPGA完成整个工程还是需要一部分串行的控制代码,如何在并行设计的电路里做出串行工作的代码,这就是状态机要解决的问题。
这里我们先插入一点背景来解释:我们以宋丹丹的冰箱装大象为例,请问把大象装进冰箱一共需要几步?三步!把冰箱门打开,把大象装进去,关上冰箱门——我们以代码形式表示
reg 大象,冰箱; always@(posedge clk) case(state): 4'd0:begin//状态机编码 打开冰箱门;//当前状态信号输出代码 if(门开了)//转移条件判断 state <= state + 4'd1;//跳往下一个状态机 end 4'd1:begin 把大象装进去; state <= state + 4'd1; end 4'd2: begin 把冰箱门关上; state <= 4'd0; end default:state <= 4'd0; endcase
Verilog状态机核心代码(非最佳,仅作演示)
两份代码有两个比较点需要关注:
第一,reg并没有和C语言中的int一样,马上声明马上用,而是放在执行范围(always)之外。
第二,本来在C语言中连续的三个步骤,在状态机中却被用state强行分割成了三个部分,每个state的数字对应一个状态,每个时钟完成一个步骤,state加一也就是切换下一个状态。
这里就要深刻理解Verilog的执行逻辑——每一个clk(准确点说是always中的触发条件,但是绝大多数或者通常来说指clk)都会使对应always内部代码运行一遍。C一路向下(除非遇到goto这种流氓)一般不会跳回去,Verilog在执行时确实也是一路向下,但是每触发一次,就会从头再来。这样就可以解释上面两点:reg之所以放在外面是因为它只执行一遍声明,没必要每次都跑一遍;为了不让三个步骤在一个触发内执行完,强行插入state作为状态机调节执行顺序。
这就是状态机——那么为什么不一次写完三个步骤而是分成三个时钟的状态机?
你可以从很多个方面来理解:
第一,如果所有的功能都塞到一个时钟触发完成,是不是需要极其庞大的资源,如果考虑多个时钟完成,那么会不会有重复的操作和资源可以利用?
第二、逻辑电路是有具体的电路延时的,虽然一般远小于时钟周期,但是也经不起无限制的塞啊,塞多了,一个时钟干不完了,不就实现不了功能了?
第三,大多数情况下步骤间不是连续的,可能有各种延时,需要插入一段代码使FPGA进入等待期。举个例子,你家炒菜的时候是一次性就按顺序把所有调料加完了?当然不是,加一点,等一会,再加一点——程序不也是这样吗?
第四,将执行分步的好处在于方便调试。在调试时,只需要调出状态机的参数,看看哪一步出了问题;如果五六七八步都放在一个触发内执行,出了BUG很难知道哪一步出了问题。
当然,我们也不是提倡把所有的操作都拉成很长很长的状态机,这里涉及的问题是资源重要还是时间重要?我们上面说过的,受制程福利,现在的主流变成是资源换时间了。
接下来看状态机的组成元素
状态机实际上也是一个一个的状态组成了,每一个状态虽然代码条件输出各不相同,但是他们应该都具有相似的结构,这里我就提取了一个状态作为讲解:
4'd0:begin//状态机编码 打开冰箱门;//当前状态信号输出代码 if(门开了)//转移条件判断 state <= state + 4'd1;//跳往下一个状态机 end
这里的四个注释解释了状态机单个状态的具体组成:
1-每次时钟边沿的时候就会依次执行当前状态是什么(编码),
2-当前状态的执行代码是什么(输出),
3-什么时候转到下一个状态(转移条件),
4-下一个状态是什么(编码)。
当状态机被分为这几个清晰的元素后,可以做的文章就多了:
首先是编码,编码作为一种特殊的计数器,在复杂的状态机中还是要考虑计数器的时序的问题,具体来说,正常的012345顺序涉及的01变化比较复杂,比如从3的二进制011变到4的二进制100就会涉及进位和3个位翻转,如果数字更大涉及的翻转会更多——有没有一种编码,每次计数都是稳定变化的呢?有没有印象?那就是格雷码,教材上一般给了4位格雷码的计数顺序,从0到F都是每次计数只有一次01变化,这是有利于高频电路实现的。当然除了格雷码以外,独热码等也是会考虑使用的编码。当然95%的情况下直接使用1234作为状态机编码就行了,如果说数字的阅读性不高的话,可以选择添加注释,或者将编码定义成parameter类型使用,这也是常用的手法。
其次是输出,这个地方的难点在于资源的优化和操作的设计。比如这里的打开冰箱门,是用一只手还是两只手?或者说一个CLK还是两个CLK?比如这里可能涉及乘除法应该怎么优化?所以在这里,抛开具体需求单说输出的执行代码,格局小了,说不了太多。
最后是转移条件,和输出一样,也是要谈具体需求的。如何设计出资源更少、操作和性能更好的状态机是优化目标,你这个转移条件可以少用一个吗?可以提前计算来减少本次的计算量吗等等。
针对不同的编写方式,将上述元素拆解到一个,两个,三个always中执行,就构成了一段式、二段式,三段式的状态机。比如上面展示的两张截图都是一段式状态机,但是这并不是最好的状态机,只因为对于入门来说,单个always有利于思考。毕竟always多了,都是并行执行的,我怕新手处理不过来。如有需要,以下是三段式状态机的模板://第一个always,次态寄存器迁移到现态寄存器
always @ (posedge clk or negedge rst_n) //异步复位 if(!rst_n) current_state <= IDLE; else current_state <= next_state; //第二个always,转移条件判断 always @ (current_state) case(current_state) S1: if(...) next_state = S2; S2: if(...) next_state = S3; ... endcase //第三个always,输出 initial ...//变量初始化 always @ (posedge clk or negedge rst_n) case(next_state) S1: out <= 输出信号状态1; S2: out <= 输出信号状态2; default:... endcase
注:1 这里把out和输出状态抽象为了一行语句,实际上可能是多个always,每个always驱动一个信号。
2 这里的状态编码S1,S2,S3是parameter,背后数值是前面提到的独热码,格雷码等
3 这里的S1,S2,S3是顺序递进,实际上的状态机大概率不是顺序运行
3.2.8 Verilog中的例化调用
从这里之前,我们一直讨论的范围都在一个module里面——但是实际情况其实肯定不止一个module。那么问题来了,一个工程中如果存在多个module应该怎么处理调用关系?这就是例化,将一个module用一段代码来指代,插入到另一个module的代码中。由于FPGA的并行处理关系,这里的位置是和always同级的,所以不要写到always里面去了。
下面我们介绍例化代码的写法: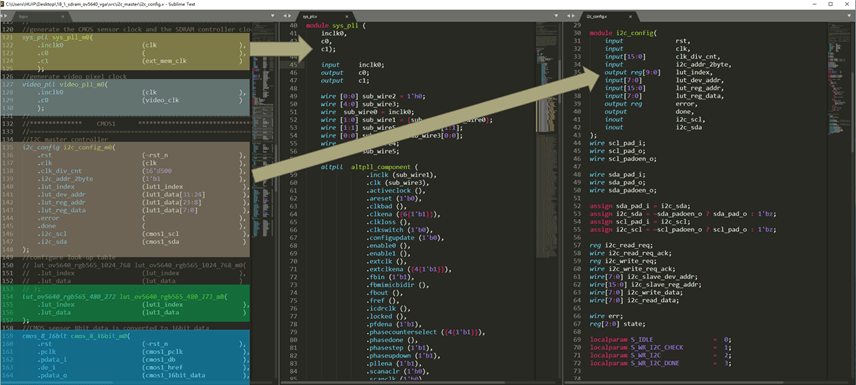 上图左边节选自一份摄像头显示的顶层文件,每个色块都是一份例化代码,其中第一个和第三个的代码在右边有所展示,我们将上述代码略微简化一点,做个更简单的例子,通过这个例子我们来学习推荐例化的写法。
上图左边节选自一份摄像头显示的顶层文件,每个色块都是一份例化代码,其中第一个和第三个的代码在右边有所展示,我们将上述代码略微简化一点,做个更简单的例子,通过这个例子我们来学习推荐例化的写法。
 被调用的代码结构为 module名+空格+任意取名+括号+端口+端口连线+反括号+分号组成。在这里test相当于姓名中的姓,name相当于姓名中的名,只要姓不改,名随便改成啥都是执行test的代码功能,这里是为了方便重复调用同一模块,但是为了区分各个模块需要不同的编号。
被调用的代码结构为 module名+空格+任意取名+括号+端口+端口连线+反括号+分号组成。在这里test相当于姓名中的姓,name相当于姓名中的名,只要姓不改,名随便改成啥都是执行test的代码功能,这里是为了方便重复调用同一模块,但是为了区分各个模块需要不同的编号。
1-另外,和module的源代码声明一致,这种指明端口和输入的例化顺序排列不影响功能,最后一个端口后面没有逗号(如果加了逗号Quartus会警告,但是不影响结果;vivado和Modelsim会直接报错,过不了编译)。
2-例化和输入端口相连的一般是常量数字或者wire、reg类型,位宽要一致,否则会将就两个位数较低的那个,多的高位就没用了;
3-和输出端口相连的只能是wire类型。
4-端口可以打乱顺序写,用不上也可以不写或者括号内留空。
5-输出可以直接被使用(除了被赋值),像这里就可直接在always里面写if(out1==5’d2)或者C=out1这种直接用法。
另外还有一种不需要注明端口,只注明输入的例化,如下所示。这种不指明端口和输入例化会将输入按照顺序匹配到对应的端口上,虽然减少了代码量,但是人看起来比较麻烦,且端口有变动的时候需要调节顺序,所以不推荐。
wire [3:0] in1,in2; wire [4:0] out1; test name ( in1, in2, ou1);
3.2.9 其他不常用语法和结构
【前排提示】以下语法只介绍其用途,如果有具体需要,需要自行百度拓展学习。我相信那个时候你应该有那个能力了。当然,这里也只是站在入门的角度,学的多了,initial,inout,for循环啥的都是信手拈来。
-
initial :变量的初始化语句,在仿真的testbench中用的较多,实用较少。虽然如果不使用这个语句,Quartus会默认把所有的变量初始化为0(在message中可以查到这条警告)。但是有些变量恰巧就不能是从0开始,比如我设计个游戏,开局3条命,结果因为Quartus的原因,进去就是0条命,需要手动重置?一般来说有些会在代码的状态机中专门增加一个初始化参数的状态机,或者是使用initial语句。(不过在01年的语法中,可以像C一样直接声明时就初始化,reg A = 1’B1这样)。
-
inout:这个和input,output组成了端口的三种属性,但是它是属于那种既可以输入又可以输出的端口(又叫三态门),直接对其赋值和output无异,赋值成Z也就是高阻态后和input无异。常见于外接电子模块的通信接口上,比如IIC,1-wire这些协议都会用到inout。它对于新手来说不常用,但是实际电子模块的运用中比较多。也就是说,如果你的算法只是FPGA内部的纯数据处理交互的,一般就不会涉及;但是如果需要外挂电子模块,大多数都是需要做inout来进行通信。
-
parameter和define:类似于define,就是把一个字符串替换成常量数字,方便编程。只不过这个参数只在这份代码文件中有效,同个工程换个文件哪怕声明一模一样的也和原来的没关系了。而define的范围是所有文件,不过这两个一般用的不多就直接写在源文件,用的多就写在单独的文件,再通过include语法导入到文件中。其中parameter还分为“本地变量”和“端口变量”,区别就在于端口变量可以在例化的时候输入参数更改parameter。
-
include:一般就是导入外部文件的define这种,改代码参数就直接改外部文件,不用翻源代码。毕竟外部文件可以只写一个,代码文件就多的去了。
-
task 和 function:完成加减乘除的部分操作,类似于C语言的函数,但是功能十分限制。
-
for:巧了,这个for的使用和C几乎一样。但是我在很多地方都看见不推荐使用for,因为这个语法在编译的时候就是暴力的叠加资源,编译时间长还比较浪费……不过在vivado中,for语句会用来做差分引脚的绑定,另一方面,多维数组不能统一赋值,想要完整初始化就得一个一个赋值,这个时候用for也是一个比较好的选择,当然这里就不细说了。
-
Unsigned,int等等一些关键字,我觉得用不上了(从入门的角度)……告辞,就酱。
3.3 在线学习网站
 对于大多数的人来说,想要让他们每个人都装一遍软件,再走一套开发流程实际上是不现实的。本图文已经是站在入门的角度推荐Quartus了,但是实际上有的人是打算一开始就上Vivado的,又不想经历Quartus,只想通过某种方法快速的学习掌握Verilog的语法——于是HDLbits 诞生了。
对于大多数的人来说,想要让他们每个人都装一遍软件,再走一套开发流程实际上是不现实的。本图文已经是站在入门的角度推荐Quartus了,但是实际上有的人是打算一开始就上Vivado的,又不想经历Quartus,只想通过某种方法快速的学习掌握Verilog的语法——于是HDLbits 诞生了。
HDLbits 是多伦多大学的开放项目,在百度上是能找到这个网站的,是一个免登录在线学习Verilog语法的网站,并且提供在线编译和验证。网站提供的两个主要功能是:提供类似闯关式的解密体验,和开放式的自由仿真。从最简单的assign a = 1;到分析仿真图反推代码,几乎是涵盖了Verilog的所有语法和使用。
但是网站是纯英文的,可能对四六级没过的人不太友好。另一方面,代码输入由于是基于网页的,所以体验不是很好,不过好歹还有关键字识别高亮,作为一个免登录的在线学习开放网站,咱也不要什么自行车了。如果有不能理解的题目,实际上经过这么一段时间,网上已经有每个题目详解和答案了。当然,大多数情况下我们并不需要将178道题目全部做完,一方面是因为我们需要将语法和具体的应用结合起来使用,不可能学完了再去使用软件和电路啥的,一般学到一半就开始搭建自己的环境和电路,逐渐脱离HDLbits了。另一方面,这个网站毕竟是入门,很多问题并不是给出题目,写出代码,验证结果这么简单。实际的项目中没有题目,没有具体的结果,我们需要在具体的项目中自己给自己“出题目”,自己给自己“验证结果”,从被动转向主动。
如果你确实没打算装Quartus,又想要实际运行或者说验证自己的Verilog学习进度,那么HDLbits确实是当下的不二之选。
更新日志
250506:初始版本